名词解释
| 名称 | 全称 | 说明 |
|---|---|---|
| GNU | GNU’s Not Unix | GNU 指的是自由软件,自由软件意味着使用者有运行、复制、发布、研究、修改和改进该软件的自由。 |
| GCC | GNU Compiler Collection | 即 GNU 编译器集合,可以编译C,C++,Java等语言; |
| gcc | GCC 中的 GNU C Compiler,特指C编译器 | |
| g++ | GCC 中的 GNU C++ Compiler,特指 C++ 编译器 | |
| LLVM | Low Level Virtual Machine | LLVM是编译器基础架构(负责优化,),可以作为多种语言编译器的后台来使用; |
| Clang | 支持C,C++和Objective-C的编译器,是基于 LLVM 开发的(后台使用 LLVM) | |
| CMake | 高级编译配置工具,用来定制整个编译流程 1. 编写 CMake 配置文件 CMakeLists.txt 2. 执行 CMakeLists.txt 生成 makefile(平台相关) 3. 使用 make 命令,配合 makefile 编译代码 |
|
| ndk-build | 与 CMake 类似,也是系统构建工具; |
编译器的工作原理
传统编译器的工作原理基本上都是三段式的,可以分为前端(Frontend)、优化器(Optimizer)、后端(Backend)。前端负责解析源代码,检查语法错误,并将其翻译为抽象的语法树(Abstract Syntax Tree)。优化器对这一中间代码进行优化,试图使代码更高效。后端则负责将优化器优化后的中间代码转换为目标机器的代码,这一过程后端会最大化的利用目标机器的特殊指令,以提高代码的性能。
| 编译器 | 前端(解析) | 后端(优化,生成机器码) |
|---|---|---|
| GCC 4.2 | GCC | GCC |
| LLVM-GCC | GCC | LLVM |
| LLVM Compiler | Clang | LLVM |
比较
-
GCC vs Clang:
- Apple 目前使用的是 LLVM 编译器,早已摒弃 GCC;
- Android NDK 从 r17 开始不再支持 GCC,而使用 Clang;
-
CMake vs ndk-build:
功能相近,CMake 更具有普遍性,所以优先使用 CMake;
编译
使用 Clang
1
2
clang --version
clang *.cpp -lstdc++;./a.out
查看编译后的汇编代码
1
2
g++ -S test.cpp -o test.s
cat test.s
#ifndef (if not defined)
仅当以前没有使用与处理器编译指令#define定义名称 COORDIN_H_ 时,才处理 #ifndef 和 #ifend 之间的语句。
为防止多次 #include 'coordin.h'的时候,下面 “something” 被多次定义;
1
2
3
4
5
6
7
8
// C++ Primer Plus # 318
// coordin.h
#ifndef COORDIN_H_
#define COORDIN_H_
// something
#endif
指针
指针与引用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
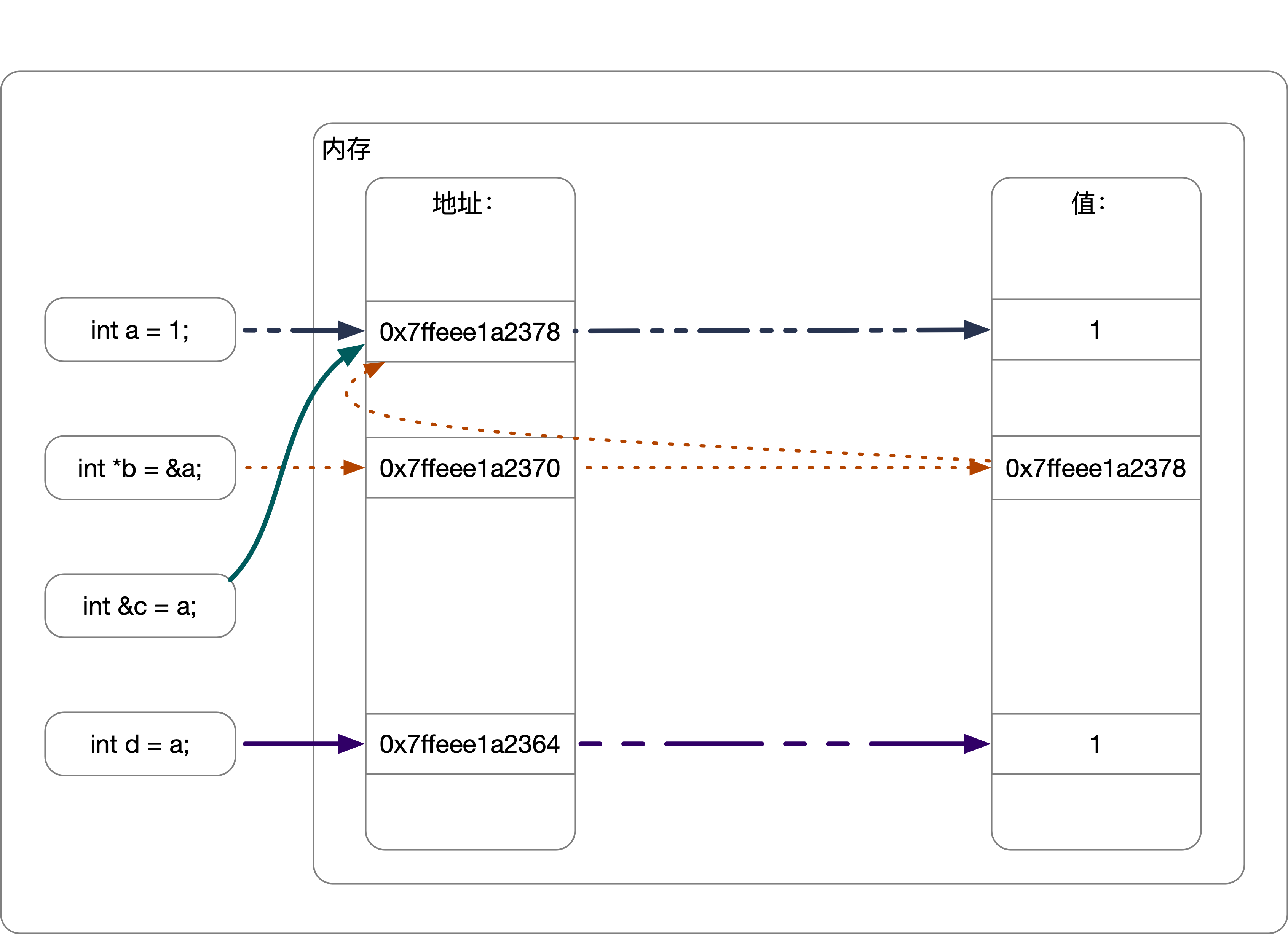
int a = 1;
int *b = &a;
int &c = a;
int d = a;
cout << "a:" << a << "," << &a << endl;
cout << "b:" << b << "," << &b << endl;
cout << "c:" << c << "," << &c << endl;
cout << "d:" << d << "," << &d << endl;
//输出
a:1,0x7ffeee1a2378
b:0x7ffeee1a2378,0x7ffeee1a2370
c:1,0x7ffeee1a2378
d:1,0x7ffeee1a2364
-
pointer & reference:
-
int *: 定义一个指针类型:- 它的值只能存地址,不能存其他的东西;
- 地址只能保存在
*x这样的对象中,其他比如int c = &a是不合法的(由继承带来的强制转换除外) *b自己也有地址,可以通过&b获取;
-
int &:定义了一个引用类型int &c = a表示 c 共用 a 的地址,c 的值当然也是和 a 是一致的;int &c = a和int d = a的区别在于:- d 的地址和 a 的地址是不一样的,只是它们的值是一样的而已,相当于是个拷贝;
- 但 c 完全等价于 a;
取值与取址
1
2
3
4
5
6
7
8
9
10
11
12
13
14
int a = 10086;
// 取址:
int *b = &a;
// 取值:
int c = *b;
cout << "a:" << a << endl;
cout << "b:" << b << endl;
cout << "c:" << c << endl;
// 输出:
a:10086
b:0x7ffeef8b33d8
c:10086
经典用法
-
参数传递
1 2 3 4 5 6 7 8 9 10
// 👇 使用 &value,传递的是引用,而非拷贝; void swap(int &val1, int &val2) { int temp = val1; val1 = val2; val2 = temp; } // 👇 新建一个 “int 指针”类型的 val1,并把需要的地址“拷贝到 val1 的值”中: void swap(int *val1, int *val2);
-
数组
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26
// 👇 数组作为参数传递,传的是首地址,所有会丢失“size”;因此一般需要传 size; void exeIntArray(int *array, int size) { int firstEle = array[0]; int firstEle2 = *array; int secEle = array[1]; // 👇 地址先往后挪一个,然后取址;结果和 array[1] 是等价的(前提是地址的连续性,所以对 数组 和 vector 是可用的,对 list 不能这么干): int secEle2 = *(array + 1); cout << "firstEle : " << firstEle << endl; cout << "firstEle2: " << firstEle2 << endl; cout << "secEle : " << secEle << endl; cout << "secEle2: " << secEle2 << endl; } int main() { int intArray[] = {1, 2, 3, 4}; exeIntArray(intArray, 4); } // 输出: firstEle : 1 firstEle2: 1 secEle : 2 secEle2: 2
函数
构造函数
-
初始化
-
自定义类,需要确保每一个构造函数都将对象的每一个成员初始化,即使是没有初始值,这是一个好习惯;
1 2 3 4 5
class Point { int x, y; // 👈 有时候会被初始化(为 0),有时候不会。 }; ... Point p;
-
在构造函数中初始化:
1 2 3 4 5 6 7 8 9 10 11 12 13
class MyClass { private: std::string name; std::int index; } // 👎 方法1: 先初始化 name 为默认值, 然后把 _name 赋值给 name; MyClass::MyClass(std::string _name) { name = _name; } // 👍👍 方法2(推荐):效率比上面的高 // 初始化顺序以定义顺序为准,而不是这里‘初值列’中的顺序 MyClass::MyClass(std::string _name) : name(_name), index() {} // 👈 如‘index’,即使是空的,也要初始化;
-
-
‘复制’构造函数
P16 &operator=(const P16 &p16)通常称为“赋值构造函数”,但这容易造成误解,其他它不是构造函数,不会新创建对象,它只是普通的运算符重载;1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45
class P16 { public: // 默认构造函数 P16() { cout << "constructor(default)[" << this << "]" << endl; } // 复制构造函数 P16(const P16 &p16) { cout << "constructor(copy)[" << this << "]" << endl; } // "=" 运算符重载,并非构造函数,不会创建新对象 P16 &operator=(const P16 &p16) { cout << "(operator=)[" << this << "]" << endl; return *this; } // 析构函数 ~P16() { cout << "~DESTROY[" << this << "]" << endl; } }; P16 getP16() { P16 p1; // 调用默认构造函数 return p1; // 将调用复制构造函数(p1 会在这里被析构) } int main() { cout << "====== start:" << endl; P16 pMain = getP16(); // 调用复制构造函数 cout << "====== step2:" << endl; P16 pMain2; // 调用复制构造函数 cout << "====== step3:" << endl; pMain2 = pMain;// 调用 operator= 运算符重载 cout << "====== exit" << endl; return 0; } // 输出: ====== start: // 👇 这里会调用3次构造函数,创建3个变量,在新的编译器中会被优化,添加`-fno-elide-constructors`参数能避免优化;可以在这里查看优化前的代码:https://cppinsights.io constructor(default)[0x7ffeeeb88030] constructor(copy)[0x7ffeeeb88080] ~DESTROY[0x7ffeeeb88030] constructor(copy)[0x7ffeeeb88088] ~DESTROY[0x7ffeeeb88080] ====== step2: constructor(default)[0x7ffeeeb88070] ====== step3: (operator=)[0x7ffeeeb88070] ====== exit ~DESTROY[0x7ffeeeb88070] ~DESTROY[0x7ffeeeb88088]
虚函数
-
经验:
- 如果要在派生类中重新定义基类的方法,通常应将基类方法声明为虚的。这样,程序将根据对象类型(而不是引用或指针的类型)来选择方法版本;
- 为基类声明一个虚析构函数也是一种惯例;如果基类的析构函数是虚的,调用派生类的析构函数后会自动调用基类的析构函数;
-
虚方法在派生类中的应用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21
class Animal { public: virtual void bark(); } class Dog { public: virtual void bark(); } int main() { Dog dog; dog.bark(); // 调用 Dog 类下的方法(没啥毛病) Animal & dog2 = dog; // 👇 如果 bark 不是虚方法,这里会调用 Animal 中的 bark 方法; dog2.bark(); }
-
重载会隐藏基类中的方法
1 2 3 4 5 6 7 8 9 10 11 12 13
class Parent { public: virtual void say(string msg); virtual void say(int i); } class Child { public: // 👇 会把 Parent 中的所有 say 方法隐藏掉; virtual void say(); }
-
纯虚函数
包含“纯虚函数”的类称为“抽象类”,它不能被初始化;
1 2
// 👇 结尾处为 ‘=0’ virtual void say() = 0;
Cpp 类
潜规则
- 在类声明中定义的变量,函数默认都是
private的; - 在类声明中定义的函数,默认为内联
inline函数; - 在构造函数中使用了
new,一般来说都需要显式定义析构函数,复制构造函数,赋值运算符。 - 在继承场景中,调用派生类的函数:
- 如果是析构函数,会自动调用基类;
- 如果是构造函数,如果没有指定则调用默认无参构造函数;
代码示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
// C++ Primer Plus # 370
// stock00.h
...
class Stock
{
private: // 👈 默认为 private,所以这个可以省略
string _company;// 👈 这里是声明,不会初始化
double _share_val;
void set_tot()
{
...
}
public:
// 👇 构造函数,可以添加默认参数,如果没有显式定义,会有默认无参构造函数
Stock(const string &company = "Bob", long share_val = 20);
Stock(Stock &stock);// 👈 ‘复制’构造函数
Stock &operator=(const Stock &stock);// 👈 ‘=’ 运算符重载
void update(double price);
~Stock();// 👈 析构函数
};
// stock00.cpp
// 👇 实现构造函数
Stock::Stock(const string &company, long share_val)
{
...
}
void Stock::update(double price)
{
...
}
// 👇 实现析构函数
Stock::~Stock()
{
cout << "bye, stock" << endl;
}
1
2
3
4
5
6
7
8
9
10
11
12
int main()
{
// 👇 和 Java 不一样,这样写就已经调用构造函数初始化了;
Stock kate; // 调用无参构造函数(如果有的话),或者全部使用默认值
kate.show();
Stock s = Stock{"CompanyName"};
Stock *s2 = new Stock;
return 0;
}
关键字
const
编译器:你想要你就说呀,你不说我怎么只要你想要不想要;
尽可能用 const,让编译器帮你尽量避免错误;
-
指针常量 & 常量指针;把这破名字忘了吧,它只会扰乱你1 2 3 4 5 6 7 8 9 10 11 12 13
int intValue = 100; int other = 10086; // 👇 *b = xxx 都不被允许 const int *b = &intValue; // 👇 c = xxx 都不被允许 int *const c = &intValue; *b = other; // 👈 Error b = &other; *c = other; c = &other; // 👈 Error
-
const 函数
1 2 3 4 5 6 7 8 9 10 11
class C { public: void func1(); void func2() const; }; int main() { const C c; c.func1(); // 👈 Error c.func2(); }
static
-
静态持续变量
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24
... // 👇 [外部链接]性[静态]持续性变量;类比于 java 中的 `public static` // 👇 会被默认初始化 int global = 1000; // 👇 内部链接性,只有当前文件能访问;类比 java 中的 `private static` // 👇 相比于上面的‘外部链接性静态变量’,static 限制了作用域; // 👇 会被默认初始化 static int one_file = 50; // 👇 效果和上述 static 一样 const int one_file2 = 100; void func() { // 👇 作用域为局部,无链接性; // 👇 会被初始化为默认值,函数执行完毕不会自动释放内存; // 👇 相比之下,static 改变了内存空间,count 被存储在‘静态存储区’ static int count; // 👇 内存空间在‘栈’中 int llama = 0; } ...
-
Singleton
为防止在使用目标变量的时候没有初始化,通用方案是放到函数中:
1 2 3 4 5
// 在 -std=c++11 条件下,是多线程安全的 static &Manager instance(){ static Manager mg; return mg; }
左值&右值
-
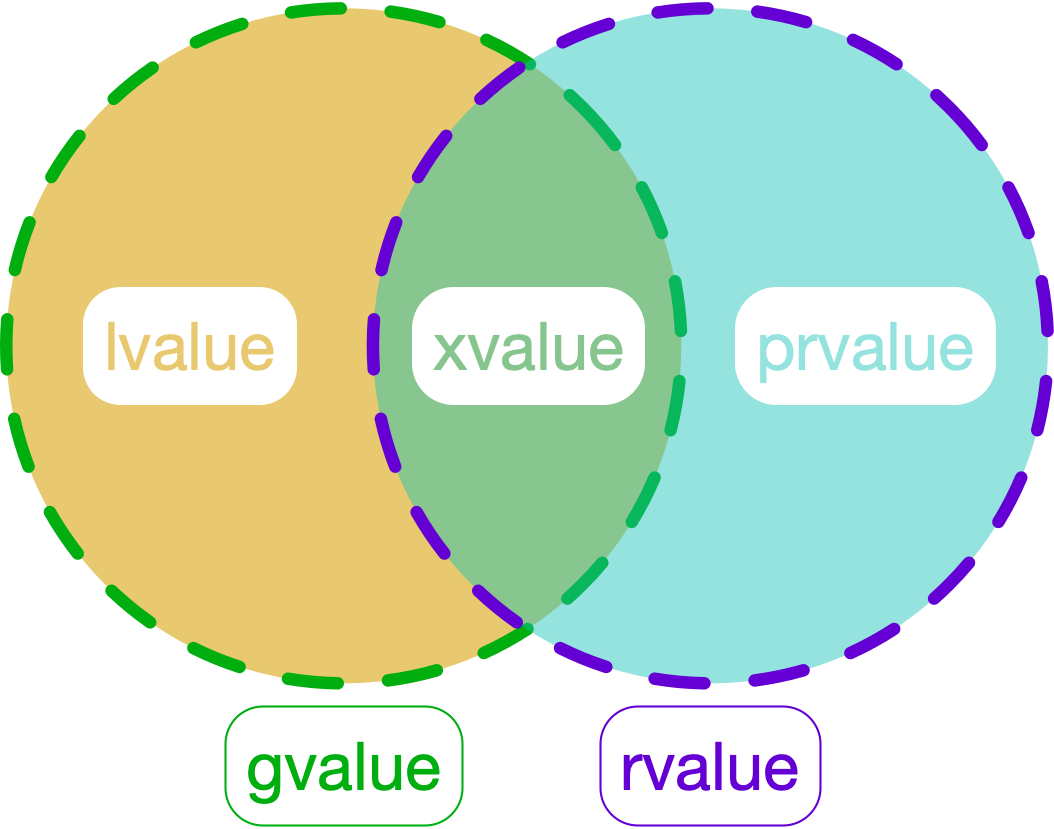
定义:
- lvalue:具名 & 不可移动
- xvalue:具名 & 可移动
- prvalue:不具名 & 可移动
- gvalue:具名
- rvalue:可移动
-
示例:
1 2
int &&a = 5; // ‘5’是右值,而‘a’是右值引用;(‘a’接收右值,但它自己是左值) int &&b = a; // ERROR! 因为‘a’是左值,而‘b’被定义为右值引用,所以不合法;
-
参考:(还没完全理解)
参考
- LLVM 与 GCC @知乎用户
- C++ Primer Plus
- Effective C++